Whisper Leak: A novel side-channel attack on remote language models
Microsoft has discovered a new type of side-channel attack on remote language models. This type of side-channel attack could allow a cyberattacker a position to observe your network traffic to conclude language model conversation topics, despite being end-to-end encrypted via Transport Layer Security (TLS).
We have worked with multiple vendors to get the risk mitigated, as well as made sure Microsoft-owned language model frameworks are protected.
The importance of language model confidentiality
In the last couple of years, AI-powered chatbots have rapidly become an integral part of our daily lives, assisting with everything from answering questions and generating content to coding and personal productivity. As these AI systems continue to evolve, they are increasingly used in sensitive contexts, including healthcare, legal advice, and personal conversations. This makes it crucial to ensure that the data exchanged between humans and language models remains anonymous and secure. Without strong privacy protections, users may be targeted or hesitate to share information, limiting the chatbot’s usefulness and raising ethical concerns. Implementing robust anonymization techniques, encryption, and strict data retention policies is essential to trust and safeguarding user privacy in an era where AI-powered interactions are becoming the norm.
In this blog post, we present a novel side-channel attack against streaming-mode language models that uses network packet sizes and timings. This puts the privacy of user and enterprise communications with chatbots at risk despite end-to-end encryption. Cyberattackers in a position to observe the encrypted traffic (for example, a nation-state actor at the internet service provider layer, someone on the local network, or someone connected to the same Wi-Fi router) could use this cyberattack to infer if the user’s prompt is on a specific topic. This especially poses real-world risks to users by oppressive governments where they may be targeting topics such as protesting, banned material, election process, or journalism. Finally, we discuss mitigations implemented by cloud providers of language models to reduce the privacy attack risks against their users. Through this process, we have successfully worked with multiple vendors to get these privacy issues addressed.
Background: Language model communication practices
Since AI-powered chatbots are used over the internet, the communications with them are often encrypted with HTTP over TLS (HTTPS), which ensures the authenticity of the server and security through encryption.
At a high level, language models generate responses by predicting and producing one token at a time based on the given prompt. Rather than constructing the entire response at once, the model sequentially calculates each token using the previous tokens as context to determine the next most likely word or phrase. This autoregressive nature means that responses are inherently generated in a step-by-step manner. Additionally, since users typically prefer immediate feedback rather than waiting for the full response to be computed, language models stream their output in chunks. This approach ensures that text is displayed as soon as possible rather than delaying until the entire response is fully formed.
Background: Symmetric ciphers
The TLS protocol is the standard means of application-level cryptography over the internet, and is most commonly used by HTTPS. Thus, the security of TLS is foundational to the confidentiality of communication.
Generally, TLS aims to use asymmetric cryptography (such as RSA or ECDH) with certificate validation to exchange session keys, which can be further used as keys in symmetric ciphers. Symmetric ciphers have also been studied and improved over the years. Symmetric ciphers fall into one of two families:
- Block ciphers: Plaintext is split into blocks of data, each block encrypted on its own, usually with some input from other blocks (known as Mode of Operation). The most common Block cipher used modernly is Advanced Encryption Standard (AES).
- Stream ciphers: Based on the key, the cipher creates a pseudo-random endless stream of bytes, which are used to manipulate the plaintext or encrypted data. Some common stream ciphers include ChaCha20, as well as AES-GCM, which turns the AES Block cipher into a stream cipher.
An important difference between Block ciphers and Stream ciphers is the data size granularity: in Block ciphers the data size always divides by the block size (for example, 16 bytes), while Stream ciphers support any data size.
Without taking compression into consideration, we can conclude the size of the ciphertext is equal to the size of the plaintext, plus a constant (for example, Message Authentication Code).
Side-channel attacks against language models
Side-channel attacks have a long history in cryptography, traditionally targeting hardware implementations by analyzing power consumption, electromagnetic emissions, or timing variations to leak secret keys.
More recently, the unique characteristics of language models have opened new avenues for side-channel analysis. Our research into Whisper Leak builds upon and is contextualized by several concurrent and recent works specifically targeting language models:
- A token length side-channel attack presented by Weiss et al. in 2024. The attack demonstrated that the length of individual plaintext tokens can be inferred from the size of encrypted packets in streaming language model responses, and in many cases, the output response being reconstructed using this information.
- A remote timing attack presented by Carlini and Nasr in 2024. The attack specifically targets the timing variations introduced by efficient inference techniques like speculative decoding.
- A timing side-channel attack via output token count presented by Tianchen Zhang, Gururaj Saileshwar, and David Lie in 2024, abusing the fact that the total number of output tokens generated by a language model can vary depending on sensitive input attributes, such as the target language in translation or the predicted class in classification.
- Timing side-channel attack through cache sharing was presented by Zheng et al. in 2024, exploiting timing differences caused by cache sharing optimizations (prefix caching and semantic caching) in language model services.
We hypothesized that the sequence of encrypted packet sizes and inter-arrival times during a streaming language model response contains enough information to classify the topic of the initial prompt, even in the cases where responses are streamed in groupings of tokens. To validate this, we designed an experiment simulating the scenario where the adversary can observe encrypted traffic but not decrypt it.
Whisper Leak methodology
In our experiment, we train a binary classifier to distinguish between a specific target topic and general background traffic. We chose “legality of money laundering” as the target topic for our proof-of-concept.
- For positive samples, we used a language model to generate 100 semantically similar variants of questions about this topic (example, “Are there any circumstances where money laundering is legal?”, “Are there international laws against money laundering?”). Eighty (80) variants were used for training and validation, and 20 were held out for testing generalization.
- For negative noise samples, we randomly sampled 11,716 unrelated questions from the Quora Questions Pair dataset, covering a wide variety of topics.
- Data collection was performed for each language model service individually, recording response times and packet sizes via network sniffing (via tcpdump), shuffling the order of positive and negative samples for collection, as well as introducing variants by inserting extra spaces between words to avoid caching interference risk. We chose a standard of language model temperature = 1.0 to encourage language model response diversity.
- See Figure 2 below for examples of the target and noise prompts used.

Post data-collection, we evaluated three different machine learning models, each of which was evaluated in three modes (time-only, packet-size only, or both):
- LightGBM: A gradient boosting framework.
- LSTM-based (Bi-LSTM): A recurrent neural network architecture suitable for sequential data.
- BERT-based: Using a pre-trained transformer model (DistilBERT-uncased) adapted with extended tokens representing size and time buckets for sequence classification.
We evaluated the performance using Area Under the Precision-Recall Curve (AUPRC), which is a measurement of a cyberattack’s success for imbalanced datasets (many negative samples, fewer positive samples). In the following table, we illustrate the results:
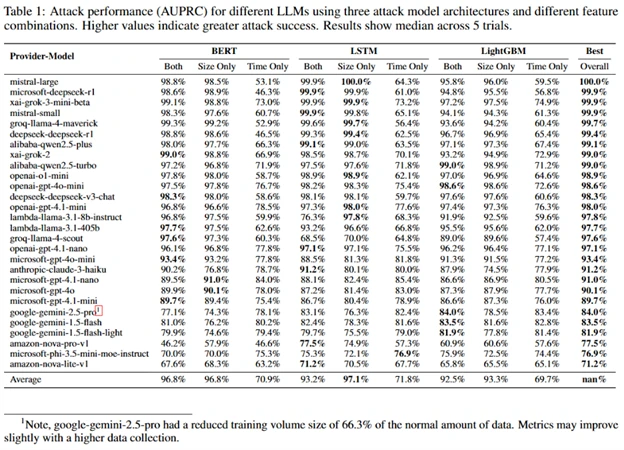
A quick look at the “Best Overall” column shows that for many models, the cyberattack achieved scores above 98%. This tells us that the unique digital “fingerprints” left by conversations on a specific topic are distinct enough for our AI-powered eavesdropper to reliably pick them out in a controlled test.
What this means in the real world
To understand what this means practically, we simulated a more realistic surveillance scenario: imagine a cyberattacker monitoring 10,000 random conversations, with only one conversation about the target sensitive topic mixed in. Even with this extreme imbalance, our analysis shows concerning results.
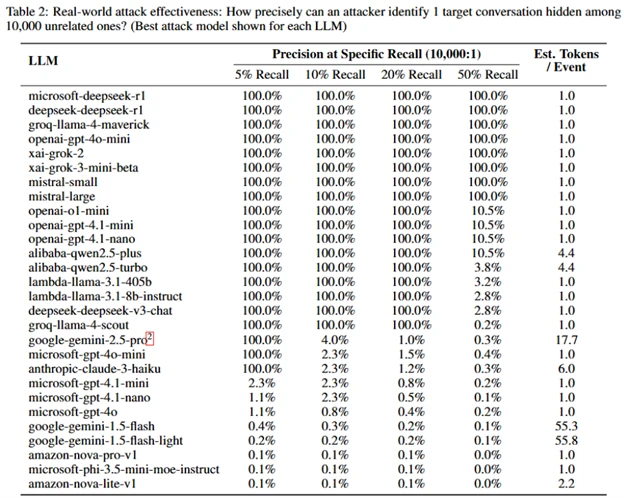
For many of the tested models, a cyberattacker could achieve 100% precision (all conversations it flags as related to the target topic are correct) while still catching 5-50% of target conversations. In plain terms: nearly every conversation the cyberattacker flags as suspicious would actually be about the sensitive topic—no false alarms. This level of accuracy means a cyberattacker could operate with high confidence, knowing they’re not wasting resources on false positives.
To put this in perspective: if a government agency or internet service provider were monitoring traffic to a popular AI chatbot, they could reliably identify users asking questions about specific sensitive topics—whether that’s money laundering, political dissent, or other monitored subjects—even though all the traffic is encrypted.
Important caveat: these precision estimates are projections based on our test data and are inherently limited by the volume and diversity of our collected data. Real-world performance would depend on actual traffic patterns, but the results strongly suggest this is a practical threat, not just a theoretical one.
This is a starting risk level
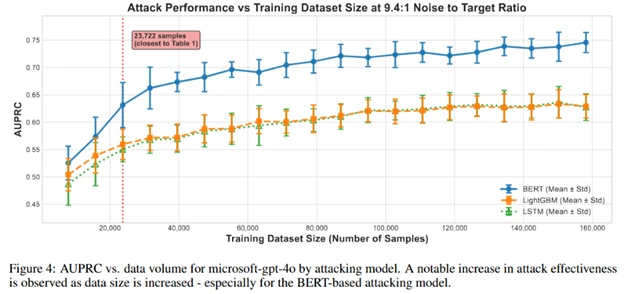
The cyberthreat could grow worse over time. These results represent a baseline risk level. Figure 4 below shows that attack effectiveness improves as cyberattackers collect more training data. In extended tests with one tested model, we observed continued improvement in attack accuracy as dataset size increased. Combined with more sophisticated attack models and the richer patterns available in multi-turn conversations or multiple conversations from the same user, this means a cyberattacker with patience and resources could achieve higher success rates than our initial results suggest.
Working with industry partners and mitigation
We have engaged in responsible disclosures with affected vendors and are pleased to report successful collaboration in implementing mitigations. Notably, OpenAI, Mistral, Microsoft, and xAI have deployed protections at the time of writing. This industry-wide response demonstrates the commitment to user privacy across the AI ecosystem.
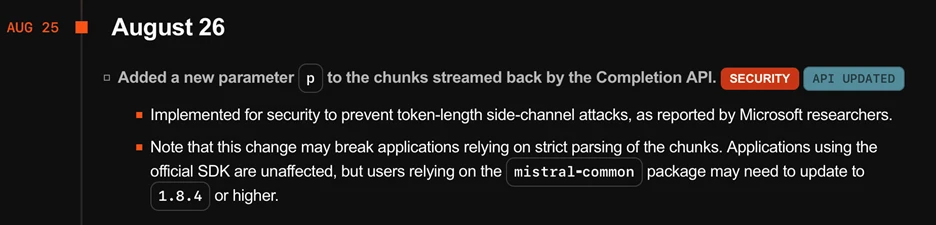
OpenAI, and later mirrored by Microsoft Azure, implemented an additional field in the streaming responses under key “obfuscation,” where a random sequence of text of variable length is added to each response. This notably masks the length of each token, and we observed it mitigates the cyberattack effectiveness substantially. We have directly verified that Microsoft Azure’s mitigation successfully reduces attack effectiveness to levels we consider no longer a practical risk.

Similarly, Mistral included a new parameter called “p” that has a similar effect.
What users can do
While this is primarily an issue for AI providers to address, users concerned about privacy can additionally:
- Avoid discussing highly sensitive topics over AI chatbots when on untrusted networks.
- Use VPN services to add an additional layer of protection.
- Prefer providers who have implemented mitigations.
- Use non-streaming models of large language models providers.
- Stay informed about provider security practices.
Source code
The models and data collection code are publicly available under the Whisper Leak repository. In addition, we have built a proof-of-concept code that uses the models to conclude a probability (between 0.0 and 1.0) of a topic being “sensitive” (related to money laundering, in our proof-of-concept).
Technical report
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
Microsoft Ignite
Join us at Microsoft Ignite to explore the latest solutions for securing AI. Connect with industry leaders, innovators, and peers shaping what’s next.
San Francisco on November 17-21
Online (free) on November 18-20

The post Whisper Leak: A novel side-channel attack on remote language models appeared first on Microsoft Security Blog.
Source: Microsoft Security